In the high-stakes world of pharmaceutical development, the emergence of biosimilars—medicinal products designed to be highly similar to existing reference biologics—has been a cornerstone for improving patient access to life-saving therapies. However, the path to market for these drugs is historically arduous, expensive, and technically complex. A landmark systematic review recently published in the journal Pharmaceuticals (Vol. 19, No. 5) suggests that the industry is on the cusp of a technological breakthrough: the integration of Machine Learning (ML) into every stage of the biosimilar lifecycle.
Authored by Vannessa Duarte and Tomas Gabriel Bas of the Universidad Católica del Norte in Chile, the study, titled "Advances in Biosimilars: A Systematic Review of Machine Learning Applications," provides a comprehensive roadmap of how artificial intelligence is moving from theoretical research into the practical, industrial-scale production of high-quality, affordable biologics.
Main Facts: A New Era for Biopharmaceutical Engineering
Biosimilars are not simple chemical generics. Because they are derived from living organisms, they are inherently complex, making the demonstration of "high similarity" to the reference product a rigorous regulatory requirement. Historically, this has required massive longitudinal studies and extensive laboratory analysis.
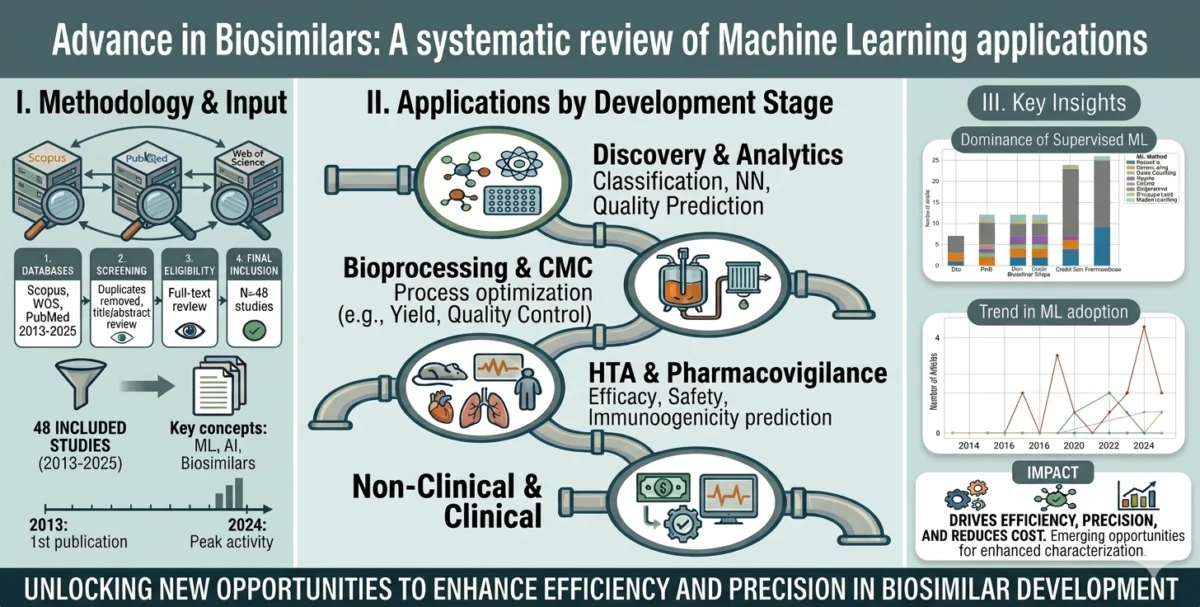
The study by Duarte and Bas synthesizes 44 peer-reviewed research papers to demonstrate how ML is fundamentally changing this narrative. The core finding is that ML is no longer a peripheral tool; it has become a central engine in two critical areas: manufacturing optimization and analytical comparability.
Key Takeaways:
- Process Efficiency: By leveraging neural networks and ensemble models, manufacturers can now fine-tune the highly sensitive conditions required to grow biological cells, ensuring that the final product remains within strict "similarity" windows.
- Analytical Precision: Machine learning algorithms are now capable of analyzing complex spectral and glycan data—tasks that previously required significant manual intervention—to confirm that a biosimilar’s molecular structure matches its reference counterpart with extreme accuracy.
- The Maturity Gap: While manufacturing and analytical applications have reached a high level of maturity, the researchers noted that ML applications in clinical prediction and long-term pharmacovigilance are still in their infancy, representing the next frontier for the industry.
Chronology: The Path to Integration
The development of this systematic review reflects the accelerating timeline of AI in life sciences. The research process was conducted in early 2026, marking a critical point where enough peer-reviewed data had finally accumulated to allow for a comprehensive mapping of the field.
- March 19, 2026: Submission of the systematic review to Pharmaceuticals. This date reflects the culmination of a rigorous data-gathering phase involving the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) framework.
- May 2, 2026: Following a period of peer review and necessary refinements to ensure the methodology met the highest scientific standards, the article was officially revised.
- May 5, 2026: The study was formally accepted for publication, signaling the academic community’s recognition of the critical importance of AI-driven pharmaceutical development.
- May 8, 2026: Official publication of the findings, providing the industry with a definitive map of where ML is currently being utilized and where it can be further deployed to reduce development costs and timelines.
Supporting Data: Mapping the Technological Landscape
To arrive at their conclusions, Duarte and Bas employed a stringent selection process. By querying the Scopus, PubMed, and Web of Science databases, they filtered thousands of records down to 44 high-impact, original peer-reviewed studies. Each included study had to meet a specific criterion: it had to implement a data-driven ML method to solve a problem directly relevant to the biosimilar lifecycle.
The data reveals a clear hierarchy of adoption:
- Supervised Learning: This remains the most prevalent method. It is used extensively in process control, where historical data is used to train models that predict how slight variations in temperature, pH, or nutrient input affect the final quality of the biological product.
- Neural Networks: These are increasingly deployed for spectral analysis. Because biologics are highly sensitive, the ability of deep learning models to identify minute variations in a drug’s molecular "fingerprint" is becoming indispensable for regulatory approval.
- Ensemble Models: These are favored for complex decision-making in the manufacturing suite, where multiple models are combined to create a more robust prediction than any single algorithm could achieve alone.
The research also highlights that while these tools are excellent at characterizing the product, there remains a "translational gap" in clinical application. Predictive models for how a patient might react to a biosimilar over years of treatment (pharmacovigilance) are currently hindered by smaller, more fragmented datasets compared to the high-volume data produced in the manufacturing plant.
Official Perspectives: Translating Research into Policy
The significance of this review lies not just in its technical assessment, but in its potential to influence regulatory and industrial strategy. The authors emphasize that the primary mission of biosimilars—providing high-quality, affordable therapy—is directly supported by these digital tools.

In their conclusions, Duarte and Bas argue that the traditional approach to pharmaceutical development is "data-rich but insight-poor." By applying ML, developers can move beyond descriptive statistics to predictive modeling. This shift is essential for companies aiming to reduce the "time-to-market" for biosimilars. If a developer can prove similarity through a combination of high-precision analytical ML and clinical data, it may eventually lead to leaner, faster, and more cost-effective clinical trial designs.
The review serves as a call to action for pharmaceutical firms to invest in data architecture. Without a robust data infrastructure capable of supporting advanced analytics, the ability to capitalize on these ML breakthroughs remains limited.
Implications: The Future of Biosimilar Development
The implications of this research are profound for both the pharmaceutical industry and the global healthcare economy.
1. Cost Reduction and Accessibility
The high cost of biologics is a major barrier to global healthcare equity. By shortening the R&D cycle through ML-optimized manufacturing and automated comparability studies, developers can significantly lower the overhead costs associated with biosimilar development. These savings are the primary mechanism by which biosimilars eventually become more affordable for patients.
2. A Paradigm Shift in Regulatory Standards
Regulators, such as the FDA and EMA, are increasingly tasked with evaluating data generated by AI. This systematic review provides a baseline for understanding which ML methods are "mature" enough for regulatory submission. As these models become more transparent and explainable, they may become standard practice in demonstrating biosimilarity, moving the field away from overly reliant, resource-heavy clinical studies.
3. Strengthening Safety Assessments
One of the most promising, albeit currently underutilized, areas mentioned is pharmacovigilance. As more biosimilars enter the market, the ability to monitor real-world performance using ML—detecting rare adverse events or subtle immunogenicity signals—will be vital. The authors emphasize that as we collect more longitudinal data, ML will be the only way to manage the complexity of post-market safety surveillance at scale.
4. Strategic Opportunities for Developers
The study concludes that the "map" it provides—differentiating between mature and emerging applications—serves as a strategic guide for biosimilar developers. Companies that prioritize the integration of ML in the early stages of manufacturing and analytical design will likely gain a competitive advantage in both speed and quality.
Conclusion: A Data-Driven Horizon
The work of Duarte and Bas confirms that the biosimilar sector is no longer just a biological challenge; it is increasingly a data-science challenge. By providing a clear, systematic review of where machine learning stands today, the authors have illuminated the path forward.
As the pharmaceutical industry continues to navigate the complexities of biologics, the ability to harness the power of artificial intelligence will likely determine the next generation of leaders in the field. The convergence of life sciences and digital technology, as evidenced by this study, promises a future where high-quality, complex medicines are not only more affordable but are developed with a level of precision that was previously unthinkable. For patients, clinicians, and manufacturers alike, this represents a significant step toward a more efficient and equitable global health system.