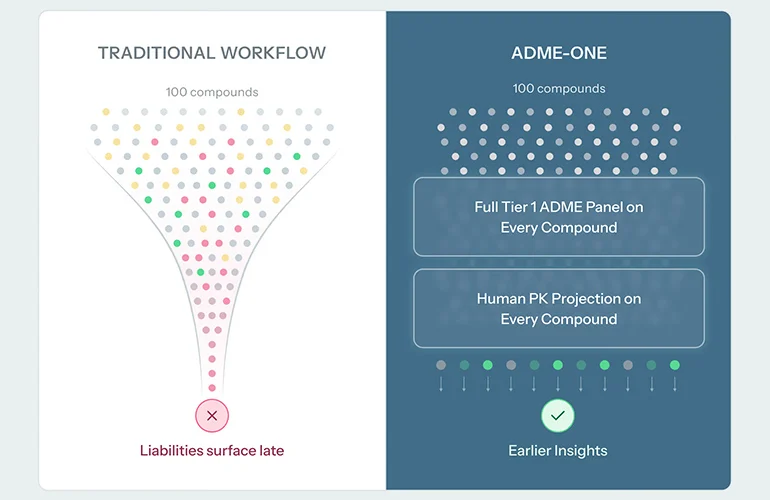
In the traditional landscape of small-molecule drug discovery, the timeline is often dictated by a rigid, linear progression. Medicinal chemistry teams spend months—and significant capital—synthesizing compounds to achieve high potency, only to face a "reality check" later in the process: the dreaded ADME (Absorption, Distribution, Metabolism, and Excretion) profiling. By relegating these critical pharmacokinetic (PK) evaluations to the "lead optimization" stage, many programs risk discovering that their most potent leads are biologically non-viable, forcing them to pivot or abandon years of effort.
A new strategic alliance between Ginkgo Datapoints, Tangible Scientific, and Inductive Bio is aiming to dismantle this outdated model. By launching "ADME-One," a high-throughput platform that integrates AI-driven modeling with automated laboratory workflows, the trio intends to move pharmacokinetic projections from the tail-end of development to the very first step: hit identification.
The Core Concept: Front-Loading Pharmacokinetics
The fundamental hypothesis behind ADME-One is simple yet transformative: what if medicinal chemists could access human PK projections and dose estimations at the same time they receive their initial potency readouts?
"We asked: Could we pull together all the assays needed to get your first projection of human PK at a price point where you’d now be doing this on most, if not all, of the compounds coming through?" explains Alex Taylor, Ph.D., Head of Medicinal Chemistry at Inductive Bio.
By embedding these capabilities into the first tier of assays, the platform allows teams to filter out "potency-traps"—compounds that bind well but lack the necessary pharmacokinetic profile to succeed in a human subject—before they consume precious R&D cycles.
A Chronology of Collaboration: The Mechanics of ADME-One
The integration of three distinct specialized entities creates a closed-loop system designed for efficiency, speed, and data integrity. The workflow functions through a highly synchronized division of labor:
- Compound Logistics (Tangible Scientific): The process begins with Tangible Scientific, which manages the physical custody of chemical samples. By handling intake, precision plating, and real-time tracking, they ensure that the "logistics bottleneck" is eliminated, allowing for rapid movement of compounds into the testing pipeline.
- Automated Lab Execution (Ginkgo Datapoints): Once the samples are prepared, they move to Ginkgo Datapoints’ automated laboratory in Boston. The facility executes five critical Tier 1 assays end-to-end: microsomal stability, cell permeability, kinetic solubility, CYP inhibition, and plasma protein binding. Because these are performed via high-throughput robotics, the turnaround time is reduced from the industry-standard "weeks" to mere "days."
- Predictive Modeling (Inductive Bio): The raw data from these assays is then funneled into Inductive Bio’s "Compass" platform. Here, machine learning algorithms synthesize the disparate assay readouts into a single, cohesive human PK projection. This allows chemists to rank compounds not just by their raw affinity, but by their projected performance in a clinical setting.
Supporting Data: Why "Dose" is the Ultimate Metric
The push for early-stage human dose estimation is not merely a technical preference; it is a clinical imperative. As noted by Dr. Taylor, the ultimate goal of any medicinal chemistry program is to find a drug that is both effective and safe at a tolerable dose.
Historical data, including research published in Hepatology, underscores the importance of this metric. Studies have indicated a correlation between high daily dosages—particularly those exceeding 50 mg per day—and an increased risk of severe adverse events, such as drug-induced liver injury (DILI). While high-dose drugs can certainly be safe, the "rule-of-two" (high dose combined with high lipophilicity) serves as a classic early warning signal for researchers.
Furthermore, lower-dose compounds generally offer superior pharmacokinetic profiles, easier formulation, and, crucially, better patient adherence. By integrating these considerations at the hit identification stage, ADME-One enables teams to steer away from "high-risk" chemical scaffolds that might otherwise look promising in a vacuum of isolated potency data.
The contrast between compounds like fluconazole (small, polar, low protein binding) and itraconazole (highly lipophilic, high protein binding, extensive metabolism) serves as a potent reminder of the complexity of ADME. Both are successful drugs, but they achieved their status through different pharmacokinetic pathways. The ADME-One platform aims to provide the context needed to identify these "diamond in the rough" molecules that might otherwise be discarded during the standard screening-funnel process.
The Economic and Geopolitical Drivers
The current climate in the pharmaceutical industry is defined by an intense focus on capital efficiency. The "screening-funnel" approach, while historically standard, is increasingly viewed as an expensive luxury that smaller biotech firms can ill afford.
"The mantra in the whole tech and pharma world right now is to stay lean, be cost-competitive, be cost-conscious," Taylor observes.
Beyond internal cost pressures, the platform addresses growing geopolitical concerns regarding data sovereignty and supply chain security. As U.S. and European developers face pressure to repatriate preclinical work—fueled by the legislative landscape of the BIOSECURE Act—the ADME-One platform offers a fully domestic alternative to offshore Contract Research Organizations (CROs). By keeping the entire workflow within the U.S. and providing faster results, the consortium positions itself as a strategic partner for companies looking to mitigate the risks of international reliance.
Data Security and the Consortium Model
A major hurdle for any collaborative AI platform is the "data dilemma": how do you train high-performance machine learning models on proprietary chemistry without compromising the intellectual property of the participants?
Inductive Bio has established a unique legal and technical architecture to solve this. The company operates a consortium model that is legally separated from the three-company partnership. Within this framework:
- Data Pooling: Partners contribute their data into a secure pool that trains the global machine learning models.
- Data Siloing: No single partner can access the raw data of another, ensuring competitive intelligence remains protected.
- Localized Fine-Tuning: When a specific customer uses the platform, the global model is fine-tuned to their specific chemical series, providing a localized boost in predictive accuracy without exposing the core data to the public or other members.
Taylor notes that the team has invested heavily in engineering to ensure that the pooled data cannot be "reverse-engineered." This prevents firms from deducing their competitors’ chemical directions by analyzing the outputs of the shared models.
Implications for the Future of Drug Discovery
The long-term goal of the ADME-One project is to create a "virtuous cycle" of discovery. As the consortium grows, the chemical diversity of the training data increases, which in turn improves the accuracy of the global models.
Inside a typical drug discovery program, this manifests as an iterative loop:
- Chemists design molecules using the Inductive platform, informed by real-time ADME predictions.
- Selected compounds are synthesized and tested via the Ginkgo/Tangible/Inductive workflow.
- The resulting experimental data validates or refines the original predictions.
- This feedback loop continuously updates the model, making it smarter for the next round of design.
The Role of Science in an AI-Driven World
Despite the high-tech nature of the platform, the team remains grounded in the realities of scientific endeavor. Dr. Taylor is quick to remind stakeholders that AI is not a replacement for experimental science.
"Drug discovery is science at the end of the day, and science is not engineering," he emphasizes. "There’s still so much that needs to happen empirically. You can give your best guess of what a compound is going to do, but at the end of the day, you need to reduce it to practice, synthesize it, and test it."
In this view, the ADME-One platform does not replace the chemist; it empowers them. It acts as a highly effective filter, ensuring that the limited time, budget, and labor of a research team are spent on the molecules with the highest probability of clinical success.
By removing the "guesswork" from the early stages and providing actionable human PK projections, Ginkgo, Tangible, and Inductive Bio are not just providing a service; they are advocating for a more efficient, evidence-based approach to the very beginning of the drug discovery journey. As the industry continues to grapple with the rising costs of R&D and the persistent challenges of clinical failure, tools that offer earlier, faster, and more accurate data will likely become the standard for the next generation of therapeutic development.