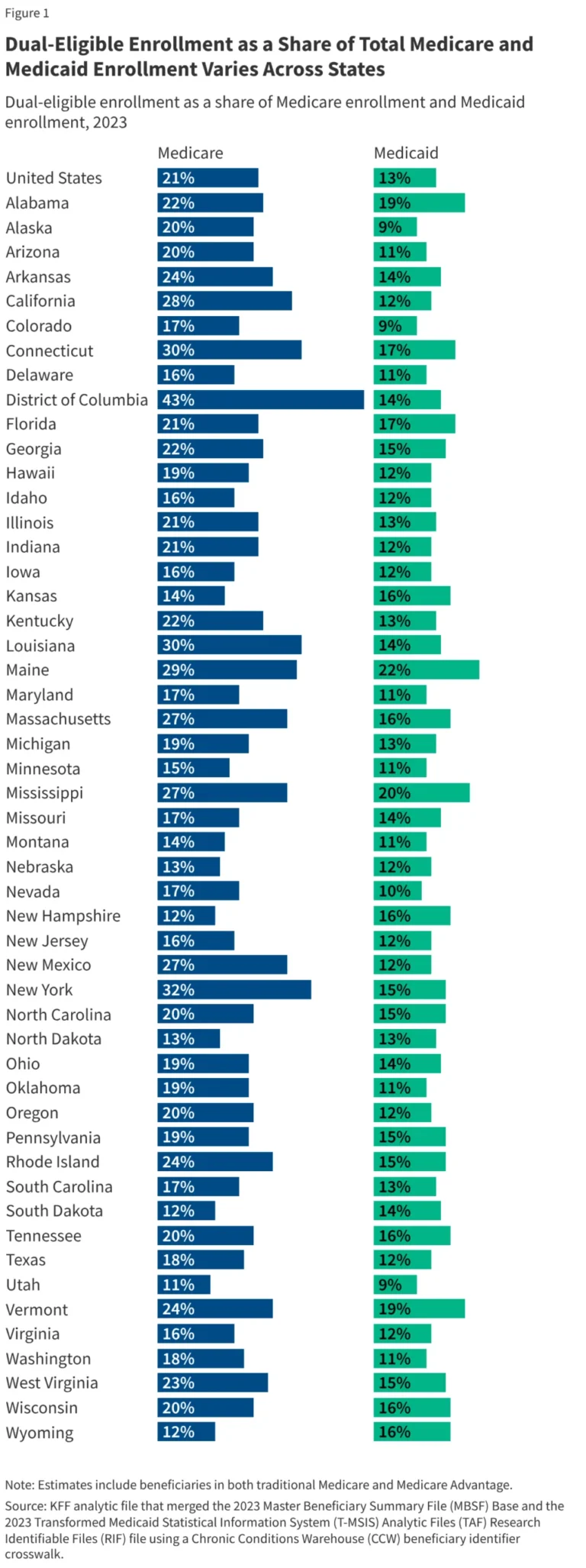
In the rapidly evolving field of precision medicine, the study of Alzheimer’s disease (AD) has reached a critical inflection point. For decades, the genetic architecture of this debilitating neurodegenerative condition has been mapped predominantly through the lens of European-ancestry cohorts. While this foundation provided essential insights, it left a profound "knowledge gap" regarding how AD manifests in diverse populations.
A groundbreaking study published in The American Journal of Human Genetics (AJHG) by Xinyu Sun and his colleagues is now challenging these historical biases. By employing a sophisticated multi-ancestry Transcriptome-Wide Association Study (TWAS) framework, the research team has successfully identified both shared and population-specific genetic drivers of Alzheimer’s disease. This work not only enhances our understanding of the disease’s biological underpinnings but also advocates for a more equitable and scientifically robust approach to genetic research.
The Core Challenge: Why Ancestry Matters in Genetics
The motivation behind this project was rooted in a fundamental observation: Alzheimer’s disease risk, prevalence, and progression rates differ significantly across global populations. However, until recently, the vast majority of transcriptomic and genetic data—the "blueprints" of disease—were derived from non-Hispanic White participants.
"Alzheimer’s disease risk differs across populations, but much of the genetic and transcriptomic work in the field has historically focused on cohorts of European ancestry," explains Xinyu Sun, a PhD candidate in Biomedical & Health Informatics at Case Western Reserve University. "That makes it harder to determine which disease-associated regulatory mechanisms are shared across populations and which may be population-specific."
When genetic studies are limited to a single ancestry, they risk missing critical regulatory variants that exist in other populations. Furthermore, they fail to leverage the natural "laboratory" of human diversity, where differences in linkage disequilibrium (the non-random association of alleles at different loci) and allele frequencies can act as a natural fine-mapping tool to identify the true causal drivers of disease.
Chronology of the Research: From Data Integration to Discovery
The genesis of this study was the availability of the MAGENTA resource, a comprehensive dataset featuring whole-blood RNA-seq and genotype data from African American, Hispanic, and non-Hispanic White participants. Recognizing this as a unique opportunity to address the field’s systemic bias, Sun’s team set out to build a "population-aware" transcriptomic framework.
Phase 1: Developing the Analytical Pipeline
The researchers utilized a statistical tool known as SuShiE (Subtype-specific Summary-data-based fine-mapping). This allowed the team to fine-map cis-eQTL (expression quantitative trait loci) effects jointly across multiple populations. By creating ancestry-matched TWAS models, the team moved beyond simple association studies; they were able to pinpoint which specific regulatory variants were driving the gene expression signals linked to Alzheimer’s.
Phase 2: Refinement of Known Loci
Once the framework was established, the team applied it to known Alzheimer’s risk loci, including BIN1, PTK2B, and DMPK. Traditional Genome-Wide Association Studies (GWAS) often identify "sentinel" variants—the markers most strongly associated with the disease—but fail to identify the specific regulatory mechanism. Sun’s study successfully refined these associations, providing a much clearer picture of the biological regulation occurring at these sites.
Phase 3: Identifying Novel Candidates
Beyond refining existing data, the study yielded new insights. The researchers identified the COG4 gene as a candidate for Alzheimer’s disease specifically in non-Hispanic White participants. Functional evidence gathered during the study suggests that this gene is regulated through distal enhancer-mediated mechanisms, providing a new target for potential therapeutic exploration.
Supporting Data: The Power of Diversity
The study’s findings underscore a pivotal argument in modern human genetics: Diversity is not just a moral imperative; it is a scientific necessity.
By integrating data from three distinct ancestral groups, the researchers were able to reduce the "noise" typically found in genetic association studies. Specifically, the inclusion of multi-ancestry data significantly reduced the median number of variants per credible set. In genetics, a "credible set" is the collection of potential causal variants for a trait. A smaller credible set means higher resolution, allowing scientists to zoom in on the specific genetic "switch" responsible for disease susceptibility.
This statistical refinement provides a roadmap for future research. It demonstrates that when datasets are balanced, the computational power to distinguish between "correlated" variants and "causal" variants increases exponentially.

Expert Perspective: The Voice of the Researcher
In an interview with the editors of AJHG, Xinyu Sun emphasized that his work is as much about methodology as it is about biology. When asked what aspect of the project was most exciting, he highlighted the increased interpretability of TWAS results.
"By combining multi-population eQTL fine-mapping with TWAS, we were able to narrow many associations to compact credible sets," Sun noted. "This helped refine the regulatory interpretation beyond the sentinel GWAS variants that we usually see in standard reports."
Advice to the Next Generation
Sun, who is currently completing his doctoral training, offered poignant advice for young scientists entering the field of computational genetics. He urged trainees to avoid the "black box" trap.
"In computational genetics, it is easy to treat a method as a black box," Sun warned. "The most useful insights often come from simple, careful questions: Does this result make biological sense? Could it be driven by linkage disequilibrium, sample size, tissue context, or model assumptions? What would convince me that this signal is real?"
He also stressed the importance of interdisciplinary communication. The project required a fusion of genetics, statistics, computational engineering, and neurobiology. "Being able to communicate across those areas is just as important as technical skill," he added.
Implications for the Future of Human Genetics
The implications of Sun’s research extend far beyond the laboratory. The study serves as a call to action for the broader scientific community to rectify the current imbalance in genomic resources.
1. The Need for Equitable Data
The research highlights a sobering reality: current GWAS and molecular QTL resources remain significantly better powered for European-ancestry populations. If the goal of human genetics is to produce findings that are both generalizable and mechanistically useful, the status quo is insufficient. The community must prioritize the creation of larger, better-balanced multi-ancestry datasets.
2. Generalizability vs. Specificity
The study successfully modeled both shared genetic effects—those that appear to drive Alzheimer’s across all groups—and population-specific effects. This distinction is vital for future drug development. A treatment that works by modulating a specific gene pathway may be highly effective in one demographic but ineffective in another if the underlying regulatory variant differs. Understanding these nuances is the cornerstone of truly personalized medicine.
3. A Shift in Methodology
By demonstrating that multi-ancestry fine-mapping can resolve complex genetic signals that single-ancestry studies cannot, Sun’s work provides a template for future research in other complex diseases, such as diabetes, cardiovascular disease, and cancer.
Conclusion: A Step Toward Genomic Equity
The work of Xinyu Sun and his team at Case Western Reserve University represents a significant milestone in the quest to demystify Alzheimer’s disease. By proving that diverse datasets enhance the resolution and accuracy of genetic findings, the study effectively dismantles the idea that "more data" is the only solution. Instead, it argues that "better, more representative data" is the key to unlocking the mysteries of human health.
As the scientific community moves toward a future where precision medicine is available to all, studies like this serve as the blueprint. By combining rigorous statistical methods with a deep commitment to inclusivity, researchers are finally beginning to see the full, complex picture of the human genome—one that acknowledges our shared vulnerabilities and our unique ancestral differences.
Xinyu Sun is currently a PhD candidate in the Department of Population and Quantitative Health Sciences at Case Western Reserve University. His work continues to bridge the gap between computational statistics and clinical neurobiology.